
How PHP's Just In Time compiler works
PHP has a Just In Time compiler (JIT) since its most recent major version, PHP 8.
Here's a demo of JIT's impact on PHP. The video was recorded by Zeev, a core developer of the php engine, to demonstrate the performance difference between php 7.0 and JIT when generating fractals.
It is fair to expect great performance improvements after watching this video, especially if you remember the amazing boost when migrating from php 5 to 7. But soon you'll notice that such gains aren't for most applications (unless you do fractals for a living 🤷🏻♀️).
So before you get too hyped or too disappointed about JIT, let me explain what this thing is and how you can get the most out of it.
What is a Just In Time compiled language and why do we need it?
Let me introduce you to compilation first, I believe we will need it.
CPUs can't read english, you already know that. They can kind of read a series of bits and bytes which represent addresses, values, instructions... But guess who can't code this? That's right, us! (At least I can't 👀 (I kind of can, but... no.))
A solution to this problem is to translate something we, humans, can write into something CPUs can execute. This translation can be called "compilation". So compilation is a translation of human-readable code to machine code. Simple, oder?
Translating human-readable code to machine code can happen in three different ways: Ahead Of Time (AOT) compilation, Just In Time (JIT) compilation or, our favorite, interpretation (or Implicit Compilation).
Languages like C, C++ or Rust are AOT-compiled languages. You write the code, you compile it and the output is a binary object that a CPU immediately understands how to execute. It is called Ahead Of Time because you compile the binary object BEFORE you run it.
Languages like PHP, Java or JavaScript are interpreted. A code written in such languages will be translated into an intermediate representation and another program (a compiled one) will understand and execute such intermediate representation. It is very common to call such programs "Virtual Machines" or "Interpreters".
Normally interpreted languages have less performance and freedom when compared with AOT-compiled languages because things like memory management, CPU-targeted instructions and funky low-level tricks are not available to the user space. So another program (the interpreter) has to manage all of this plus be polyglot enough to talk to different kinds of processors and operating systems.
Languages like Java, LUA and now PHP are not only interpreted but also Just In Time compiled! They still need a VM, but their VMs are capable of compiling this intermediate representation of code into binary objects in runtime. These JIT-capable VMs operate in a hybrid mode where code is partially compiled and interpreted.
When JIT kicks in, parts of your php code will be compiled into machine code so the Zend VM (php's virtual machine) won't interpret these parts anymore. Your php code will talk directly to the CPU.
So why can't we just compile everything, then? If the VM is a bottleneck, why bother to run through it in the first place? We could just compile our php code into machine code and be happy about it.
Well, we'd have to compile to specific CPU architectures, be prepared to talk to different operating systems, be extremely clear about our variable types and perform way more bare-metal operations than we should if we want to be productive. There are decent abstractions for Golang and Rust, for example, but they aren't very practical and require control over the environment they're deployed against.
Interpreted languages, on the other hand, can be easily deployed to different servers, allow rapid development and create room for dynamic typing systems.
Just In Time compilation is potentially the best of the two worlds, combining good speed and developer experience.
Dynamic typing, as you know, is one of the core features of PHP. It is very complex and is tattooed into php's core in a way that removing the dynamic typing is almost unthinkable. Here’s a great summary on how php’s type system works.
And because of Dynamic Typing (and some other things you'll learn about below) the Just In Time compiler present in PHP is not yielding big performance gains. At least not yet.
Curious why? Keep reading!
Let's see how PHP works with and without JIT
In PHP there are three steps before executing your code: tokenizing, parsing into an AST and compiling to an intermediate representation known as Opcode.
Tokenizing (or Lexing) is the process of reading php code and splitting
it into understandable units called tokens. <?php becomes a T_OPEN_TAG,
echo becomes a T_ECHO and "Hello, friend" becomes T_CONSTANT_ENCAPSED_STRING.
A complete list of PHP's tokens can be found here.
Parsing is the process of making sense out of such tokens. In PHP parsed tokens
are organized in a tree structure named AST (Abstract syntax tree).
The AST's job is to represent what operations should be. In echo 1+1 the interpreter
should in fact understand print the result of the expression 1+1. Such tree would
look something like the following:
operation => ECHO,
operand => expression (
operation => ADD,
operand1 => 1,
operand2 => 1
)
PHP is then able to compile this tree into an intermediate representation called Opcode.
The Opcode is what is actually executed by the virtual machine, so executing is the final step. Here's a diagram illustrating how this process looks like.
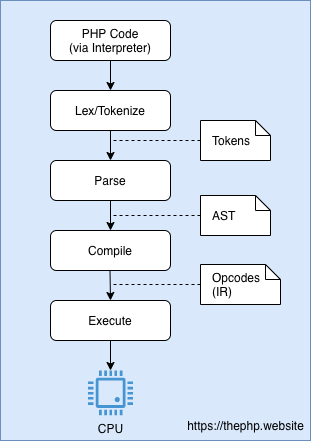
You probably realized that tokenizing, parsing and compiling code every single time can be a big bottleneck. PHP engineers thought so too and that's why the Opcache extension exists. Let's have a quick look at it.
The Opcache extension
The Opcache extension is shipped with PHP and generally there's no big reason to deactivate it. If you use PHP, you should probably have Opcache switched on.
It adds an in-memory shared cache layer to store Opcodes. So tokenizing, parsing and compiling will happen once for each file and will be shared with every request.
With Opcache extension enabled, the execution of PHP code looks like in the following diagram:
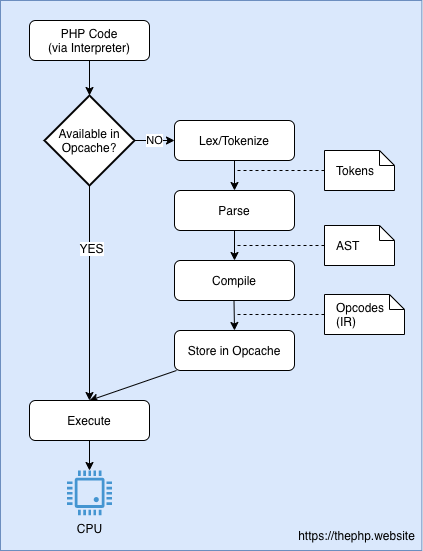
Side note: this is where PHP 7.4's preloading feature shines! It allows you to tell PHP FPM to parse your codebase, transform it into Opcodes and cache them even before you execute anything.
Enters the Just In Time compilation
While the Opcache extension will prevent PHP from tokenizing, parsing and compiling over and over again, the Just In Time compilation aims to skip the virtual machine's Opcode interpretation and let it execute machine code directly.
PHP's JIT implementation uses a C library called DynASM (Dynamic Assembler) which maps a set of CPU instructions in one specific format into assembly code for many different CPU types. So the Just In Time compiler transforms Opcodes into an architecture-specific machine code using DynASM.
The compilation happens between fetching Opcodes from cache and executing them. Since compiling Opcode into machine code can be very expensive, PHP has to decide which portions of your code might make sense to be compiled or not.
PHP then profiles Opcodes being executed by the Zend VM and checks which ones might make sense to compile. (based on your configuration)
When an Opcode is compiled its execution doesn't happen through the Zend VM handlers, they are directly executed by the CPU.
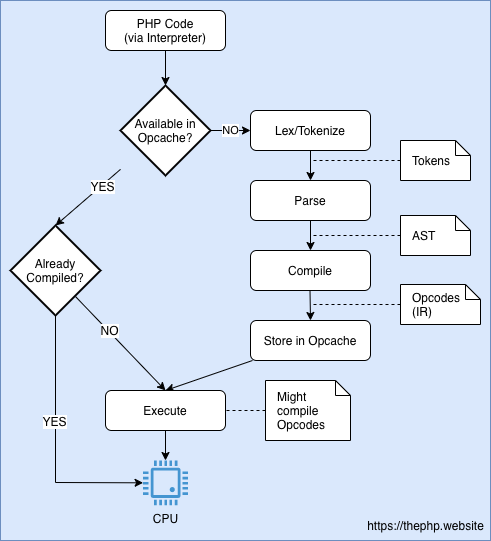
When an Opcode should be compiled is decided based on your INI configurations. You'll get more details in the next section.
How to configure JIT
Configuring JIT in PHP is very simple, there are two INI directives we need to set:
opcache.jit_buffer_size and opcache.jit. The first indicates how much memory
we're willing to allocate for compiled code, while the later one dictates how JIT
should behave.
There's also an optional directive named opcache.jit_debug for debugging purposes.
I will not cover this one here.
For example, the snippet below indicates that we're willing to give up to 100 Megabytes of compiled code, enabling AVX instruction generation, using a global linear-scan register allocator, profiling each request and jitting hot functions, optimizing the compiled code based on static type inference. (👀 WUT?)
opcache.jit_buffer_size=100M
opcache.jit=1235
To make your life easier, I’m bringing some presets that Benjamin Eberlei kindly shared in his blog:
opcache.jit=1205(JIT everything)opcache.jit=1235(JIT hot code based on relative usage)opcache.jit=1255(trace hot code for JITability, the best so far)
The opcache.jit entry is a sequence of values named "CRTO", each character can have different
behavioural effect on your application. Below I explain what each of these letters can do:
C - CPU-specific optimization
| Flag | Meaning |
|---|---|
| 0 | No optimization whatsoever |
| 1 | Enable AVX instruction generation |
R - Register Allocation Modes
| Flag | Meaning |
|---|---|
| 0 | Never perform register allocations |
| 1 | Use local linear-scan register allocation |
| 2 | Use global linear-scan register allocation |
T - JIT trigger
| Flag | Meaning |
|---|---|
| 0 | JIT everything on first script load |
| 1 | JIT functions when they execute |
| 2 | Profile first request and compile hot functions on second requests |
| 3 | Profile and compile hot functions all the time |
| 4 | Compile functions with a @jit in doc blocks |
O - Optimization level
| Flag | Meaning |
|---|---|
| 0 | Never JIT |
| 1 | Minimal JIT (use regular VM handlers) |
| 2 | Selective VM handler inlining |
| 3 | Optimized JIT based on static type inference of individual function |
| 4 | Optimized JIT based on static type inference and call tree |
| 5 | Optimized JIT based on static type inference and inner procedure analyses |
I don't fully understand every term there, but the main takeaway is that you should play around with each flag and keep profiling your application to better understand what suits you better.
The performance outcomes can be quite counter intuitive. For example: higher JIT buffer sizes may lead to slower applications basically because PHP may spend more time compiling more Opcodes instead of executing them. (The bigger your buffer, the more you can compile)
Problems introduced by JIT
The Just In Time compiler will make a best effort to translate Opcodes into machine code, but of course some issues may come out of it.
Type Juggling may affect performance negatively
PHP's type system is very forgiving and its flexibility can translate to a big overhead to the Zend VM.
Translating its type juggling to machine code can end up generating compiled code that
is more expensive in runtime than interpreting it and, as far as I understand, the
strict_types mode can't help at all.
[Looking at this vm handler](this Zend VM handler), it gets clear that php's type juggling can branch into so many possibilities at runtime. Compiling all of them may end up costing way more than just interpreting it through the VM.
Debugging with JIT is a bit harder
Because JIT bypasses some VM hooks, tools like xDebug will face some trouble on tracking jitted code and this is expected.
One may argue that JIT is supposed to be a production-only feature. But it might also cause bugs by changing code behaviour unexpectedly, so not having an easy solution for debugging can be a trouble.
Maintainability
For end-users this is not really a big issue, but JIT added significant complexity to PHP's codebase and its future scope includes even crazier implementation details.
Performance Impact
PHP's performance may nearly double depending on your set up and use case. During its early implementation phase, some very impressive numbers came up:
- nikic/PHP-Parser ran about 1.3 times faster in benchmark made by Nikita Popov
- A hello world application written with Amp had about 5% speed improvement
- MessagePack benchmarks showed 1.3 to 1.5 times speed up
What do all of them have in common? They are CPU-intensive (to a degree) tasks, and these are the ones that will benefit the most from JIT in PHP.
It is still not very clear how "real-world apps" will behave with JIT, but that depends a lot on your configuration and use-case. As normally php applications do many I/O operations, they might not feel the improvement so much, but it is possible to target the JIT engine to certain spots of your application.
Areas that may benefit from JIT include: - Serialization/Deserialization - Routing - Hashing functions - Image processing
Pretty much any task that repeats often in your code and has no I/O dependency at all.
If I would guess what kind of tools we already use that could benefit immediately from JIT
If I would guess which tools we already use could benefit immediately from JIT, they'd be Composer, PSALM, PHP-Parser, PHPCS and all async php frameworks.
How will PHP look like in the future?
Many stated before that PHP hit the brick wall when it comes to performance improvements, meaning that from here on every improvement will cost more work and yield less gains.
JIT brought a new horizon to the php language. The idea that php code can be as fast as C will allow our php applications to transcend the web environment.
Crazy applications like Game Development with PHP might become more common, at least just for fun.
I believe that Swoole applications will slowly become more popular after PHP 8's release. Their long-running and async nature can benefit from JIT in a way that maybe the fast proxy -based model can't.
It is also important to mention PHP-ML which will soon see big architectural changes.
Related to JIT itself, there's already an idea to add a low-cost initial profiling that will collect sufficient data to calculate probabilities of jumps, and fetching runtime types and values. This would allow the engine to JIT only fast paths and optimize the VM-Machine Code exchange.
I hope this article was useful for you and that you managed to grasp better what PHP 8's JIT is about.
If you spotted any misconception or mistake, please don't refrain contacting me or just incrementing this Github issue. I'll be more than glad to receive your feedback and correct issues with this text asap 😉
Feel free to reach me out on twitter if you'd like to add something I might have forgotten here and don't forget sharing this with your fellow developers, it surely will add much value to your conversations!